Pytorch c10 模块详解
Categories: Framework_analysis
一 c10 模块概述
c10 模块更倾向于提供高级别的抽象和功能,而 ATen则提供了更接近硬件的底层操作。c10 主要模块包括:
- c10/core: 该子目录定义了很多基础类型和核心概念,如 Device、Stream、DataPtr、错误处理(例如 C10_ERROR 系列接口)等。
TensorImpl:Tensor 的底层实现,存储数据指针、形状(sizes)、步长(strides)、设备(device)等元信息。ScalarType:定义标量数据类型(如 kFloat、kInt)。- Device:封装了设备信息(如 CPU、CUDA 等),支持设备间的统一管理。
- Stream:提供对异步流(如 CUDA 流)的抽象,允许在不同设备上执行并行操作。
- 其他核心组件还可能包括与内存管理、后端调度相关的工具。
- c10/cuda/:作用:CUDA 设备管理、流(Stream)、事件(Event)、内存分配等。
- CUDAStream:定义 CUDA 流(cudaStream_t)抽象接口,管理异步 GPU 操作。
- CUDAGuard:设置当前设备(Device)和流(Stream)的上下文守卫。
- CUDAFunctions:CUDA 运行时 API 的封装(如设备同步、内存拷贝)。
- CUDACachingAllocator:CUDA 内存分配器,支持高效的内存池管理。
- c10/util: 包含各种实用的模板和辅助工具,例如 Optional、ArrayRef、类型特性工具等,这些工具在整个框架中帮助简化数据结构管理和算法实现。
- c10/macros: 提供了大量宏定义,用于统一错误检查、分支预测优化(如
C10_LIKELY/C10_UNLIKELY)、调试信息输出、编译器平台适配等功能。这些宏在高性能代码路径中起到优化和代码风格统一的作用。 - 其他模块:根据版本不同,c10 中可能还会包含与特定后端(例如
CUDA、hip相关)的适配代码、日志系统实现、以及与分布式或异步执行有关的工具。
二 Stream 类
2.1 Stream 抽象类
Stream 主要用于表示一个设备(通常是 GPU,比如 CUDA)上的操作队列或执行流。pytorch 中 c10 模块的 Stream 抽象定义的接口实现在 c10/core/Stream.h文件中。
Stream 抽象类定义的公有成员函数如下所示:
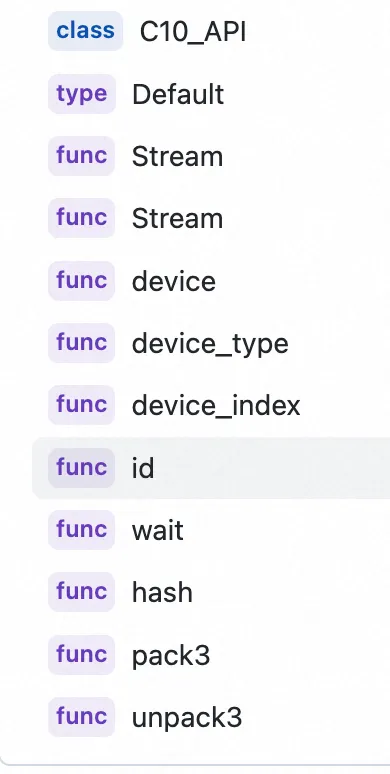
Stream 类定义代码如下所示:
using StreamId = int64_t;
class C10_API Stream final {
private:
Device device_;
StreamId id_;
public:
enum Unsafe { UNSAFE };
enum Default { DEFAULT };
/// Unsafely construct a stream from a Device and a StreamId. In
/// general, only specific implementations of streams for a
/// backend should manufacture Stream directly in this way; other users
/// should use the provided APIs to get a stream. In particular,
/// we don't require backends to give any guarantees about non-zero
/// StreamIds; they are welcome to allocate in whatever way they like.
explicit Stream(Unsafe, Device device, StreamId id)
: device_(device), id_(id) {}
/// Construct the default stream of a Device. The default stream is
/// NOT the same as the current stream; default stream is a fixed stream
/// that never changes, whereas the current stream may be changed by
/// StreamGuard.
explicit Stream(Default, Device device) : device_(device), id_(0) {}
bool operator==(const Stream& other) const noexcept {
return this->device_ == other.device_ && this->id_ == other.id_;
}
bool operator!=(const Stream& other) const noexcept {
return !(*this == other);
}
Device device() const noexcept {
return device_;
}
DeviceType device_type() const noexcept {
return device_.type();
}
DeviceIndex device_index() const noexcept {
return device_.index();
}
StreamId id() const noexcept {
return id_;
}
// Enqueues a wait instruction in the stream's work queue.
// This instruction is a no-op unless the event is marked
// for recording. In that case the stream stops processing
// until the event is recorded.
template <typename T>
void wait(const T& event) const {
event.block(*this);
}
// Return whether all asynchronous work previously enqueued on this stream
// has completed running on the device.
bool query() const;
// Wait (by blocking the calling thread) until all asynchronous work enqueued
// on this stream has completed running on the device.
void synchronize() const;
// The purpose of this function is to more conveniently permit binding
// of Stream to and from Python. Without packing, I have to setup a whole
// class with two fields (device and stream id); with packing I can just
// store a single uint64_t.
//
// The particular way we pack streams into a uint64_t is considered an
// implementation detail and should not be relied upon.
uint64_t hash() const noexcept {
// Concat these together into a 64-bit integer
uint64_t bits = static_cast<uint64_t>(device_type()) << 56 |
static_cast<uint64_t>(device_index()) << 48 |
// Remove the sign extension part of the 64-bit address because
// the id might be used to hold a pointer.
(static_cast<uint64_t>(id()) & ((1ull << 48) - 1));
return bits;
}
struct StreamData3 pack3() const {
return {id(), device_index(), device_type()};
}
static Stream unpack3(
StreamId stream_id,
DeviceIndex device_index,
DeviceType device_type) {
TORCH_CHECK(isValidDeviceType(device_type));
return Stream(UNSAFE, Device(device_type, device_index), stream_id);
}
// I decided NOT to provide setters on this class, because really,
// why would you change the device of a stream? Just construct
// it correctly from the beginning dude.
};
C10_API std::ostream& operator<<(std::ostream& stream, const Stream& s);
} // namespace c10
2.2 CUDAStream 类
Cuda API 可分为同步和异步两类,同步函数会阻塞 host 端的线程执行,异步函数会立刻将控制权返还给 host 从而继续执行之后的动作。异步函数和 stream 是 grid level 并行的两个基石
CUDAStream 是 PyTorch 管理 CUDA 异步操作的核心类,用于控制 GPU 任务的并行执行和同步。Cuda stream 对象是指一堆异步的 cuda 操作,他们按照 host 代码调用的顺序执行在 device上。Stream 维护了这些操作的顺序,并在所有预处理完成后允许这些操作进入工作队列,同时也可以对这些操作进行一些查询操作。
CUDAStream 类的代码实现在 c10/cuda/CUDAStream.h 和 CUDAStream.cpp 文件中。私有成员变量定义:
class C10_CUDA_API CUDAStream {
public:
enum Unchecked { UNCHECKED };
/// Construct a CUDAStream from a Stream. This construction is checked,
/// and will raise an error if the Stream is not, in fact, a CUDA stream.
explicit CUDAStream(Stream stream) : stream_(stream) {
TORCH_CHECK(stream_.device_type() == DeviceType::CUDA);
}
// 代码省略
private:
Stream stream_; // 公共抽象父类对象,定义在 c10/core/Stream.h
}
2, 公有成员函数。
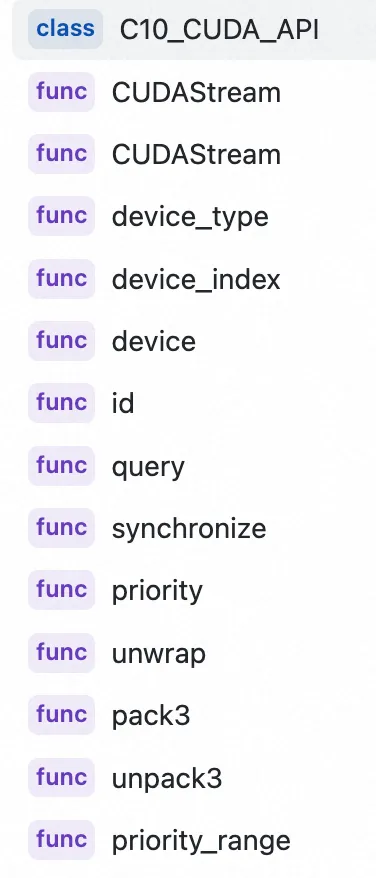
3,CUDAStream 流的创建和销毁。
- 默认流:
- 每个设备有一个默认流(Default Stream),通过
getDefaultCUDAStream函数获取默认流对象。 - 默认流是同步流,操作按顺序执行。
- 每个设备有一个默认流(Default Stream),通过
/**
* Get the default CUDA stream, for the passed CUDA device, or for the
* current device if no device index is passed. The default stream is
* where most computation occurs when you aren't explicitly using
* streams.
*/
C10_API CUDAStream getDefaultCUDAStream(DeviceIndex device_index = -1);
- 独立流:
- 通过
getStreamFromPool从流池中获取,避免频繁创建销毁流的开销。 - 独立流可以并行执行,但需要手动同步。
- 通过
/**
* Get a new stream from the CUDA stream pool. You can think of this
* as "creating" a new stream, but no such creation actually happens;
* instead, streams are preallocated from the pool and returned in a
* round-robin fashion.
*
* You can request a stream from the high priority pool by setting
* isHighPriority to true, or a stream for a specific device by setting device
* (defaulting to the current CUDA stream.)
*/
C10_API CUDAStream
getStreamFromPool(const bool isHighPriority = false, DeviceIndex device = -1);
// no default priority to disambiguate overloads
C10_API CUDAStream
getStreamFromPool(const int priority, DeviceIndex device = -1);
4,各个函数实现分析。
// 目的:确保当前流的所有 CUDA 操作执行完毕,提供一种同步机制。
void synchronize() const {
// 确保在调用 CUDA 同步操作前,将当前设备切换为流所属的设备
DeviceGuard guard{stream_.device()};
// 调用 c10::cuda::stream_synchronize() 对当前流进行同步,
// 即阻塞直到流中所有操作执行完毕,确保 CUDA 操作已完成
c10::cuda::stream_synchronize(stream());
}
2.2 Stream python 类
Stream 和 Event 的 python 类代码实现都在 torch/cuda/streams.py,分别继承自 torch._C._CudaStreamBase 和 torch._C._CudaEventBase。
Stream类包含 wait_event、wait_stream、record_event、 query 和 synchronize 等成员函数。Event类主要包含:record、wait、query、elapsed_time 和 synchronize 等成员函数。
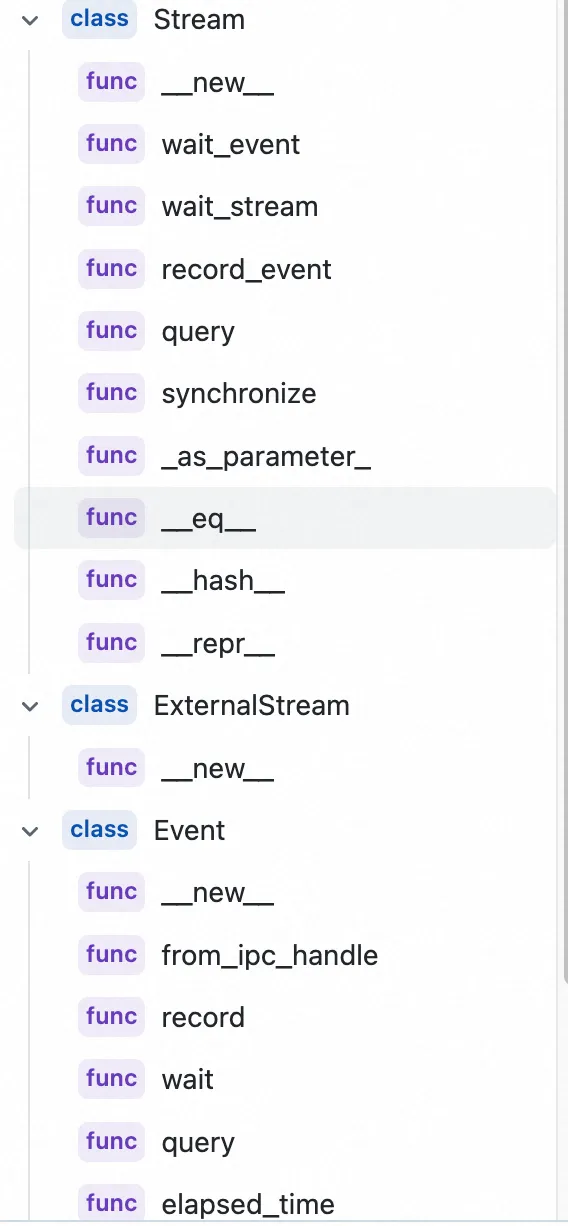
三 Event 类
3.1 Event 类
1,什么是 Event
Event 是 stream 相关的一个重要设计,用于在 CUDA Stream 中插入事件,记录 GPU 操作的时间戳或实现流间同步。Event 类的关键方法:
record(stream=None):在指定流中记录事件。synchronize():阻塞 CPU 主机线程,直到直到此事件中当前捕获的所有工作完成。wait(stream):让提交到给定 stream 的所有未来工作等待此事件。如果未指定流,则使用torch.cuda.current_stream()。elapsed_time(end_event):计算两个事件的时间差(毫秒)。query(): 提供了非阻塞式的完成状态检查机制。
2,Event 的生命周期
- 创建(cudaEventCreate):调用 cudaEventCreate() 或 cudaEventCreateWithFlags() 创建一个 Event 对象。
- 记录(cudaEventRecord):将 Event 推入指定的 stream。如果你使用默认流(即 0 或 cudaStreamDefault),则该 Event 会在所有流上顺序生效(见下文默认流语义)。
- 查询(cudaEventQuery):异步查询该 Event 是否已完成。如果为 “未完成”,函数会立即返回 cudaErrorNotReady;只有当该 Event 标记的 stream 中位于它之前的所有操作都执行完毕,query() 才会返回 cudaSuccess。
- 等待/同步(cudaEventSynchronize):阻塞当前 CPU 线程,直到该 Event 完成。
- 销毁(cudaEventDestroy):释放 Event 资源。
下图是是 c10/core/Event.h 中 Event 类的成员函数总结,各个函数的实现其实是在 c10/core/impl/InlineEvent.h 中。
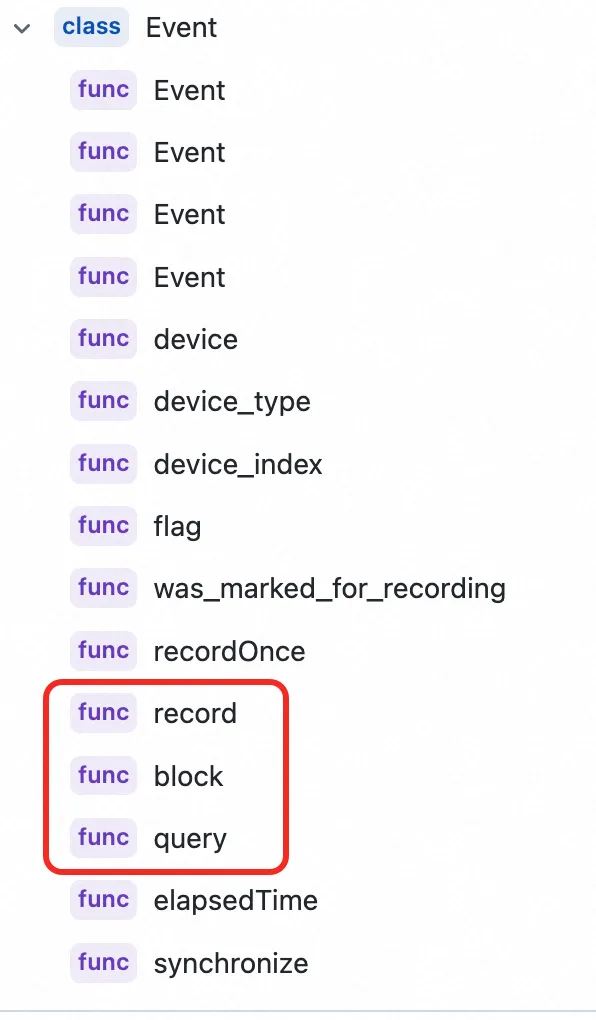
c10/core/impl/InlineEvent.h 文件中 InlineEvent 类的总结和注释如下所示:
// InlineEvent 是一个模板结构体,用于封装事件(Event)的操作,其行为依赖于具体的后端实现(通过模板参数 T 提供)。
// 注意:构造函数被删除,必须传入设备类型和可选的 EventFlag 进行初始化。
template <typename T>
struct InlineEvent final {
// 禁用默认构造函数
InlineEvent() = delete;
// 构造函数:需要传入设备类型和可选的标志参数(默认为 PYTORCH_DEFAULT)
InlineEvent(
const DeviceType _device_type,
const EventFlag _flag = EventFlag::PYTORCH_DEFAULT)
: backend_{_device_type}, // 利用设备类型初始化后端实现对象
device_type_{_device_type}, // 记录事件所属的设备类型
flag_{_flag} {} // 记录事件标志
// 禁用拷贝构造和拷贝赋值,避免误拷贝事件对象
InlineEvent(const InlineEvent&) = delete;
InlineEvent& operator=(const InlineEvent&) = delete;
// 移动构造函数,允许事件对象在移动语义下转移所有权
InlineEvent(InlineEvent&& other) noexcept
: event_(other.event_), // 传递底层事件指针
backend_(std::move(other.backend_)), // 移动后端实现对象
device_type_(other.device_type_), // 拷贝设备类型
device_index_(other.device_index_), // 拷贝设备索引
flag_(other.flag_), // 拷贝事件标志
was_marked_for_recording_(other.was_marked_for_recording_) {
// 移动后将原对象的事件指针置空,避免重复释放
other.event_ = nullptr;
}
// 移动赋值运算符,利用 swap 实现
InlineEvent& operator=(InlineEvent&& other) noexcept {
swap(other);
return *this;
}
// 交换两个 InlineEvent 对象的所有成员
void swap(InlineEvent& other) noexcept {
std::swap(event_, other.event_);
std::swap(backend_, other.backend_);
std::swap(device_type_, other.device_type_);
std::swap(device_index_, other.device_index_);
std::swap(flag_, other.flag_);
std::swap(was_marked_for_recording_, other.was_marked_for_recording_);
}
// 析构函数:若 event_ 不为空,则通过后端对象释放资源
~InlineEvent() noexcept {
if (event_)
backend_.destroyEvent(event_, device_index_);
}
// 返回事件所属设备的类型
DeviceType device_type() const noexcept {
return device_type_;
}
// 返回事件所属设备的索引
DeviceIndex device_index() const noexcept {
return device_index_;
}
// 返回事件的标志
EventFlag flag() const noexcept {
return flag_;
}
// 查询事件是否已被记录
bool was_marked_for_recording() const noexcept {
return was_marked_for_recording_;
}
// 如果尚未记录,则记录一次当前流
void recordOnce(const Stream& stream) {
if (!was_marked_for_recording_)
record(stream);
}
// 记录事件到指定流
void record(const Stream& stream) {
// 检查传入流的设备类型与事件所属设备类型是否匹配
TORCH_CHECK(
stream.device_type() == device_type_,
"Event device type ",
DeviceTypeName(device_type_),
" does not match recording stream's device type ",
DeviceTypeName(stream.device_type()),
".");
// 调用后端接口进行事件记录
// 参数:事件指针的地址、流、当前设备索引、标志参数
backend_.record(&event_, stream, device_index_, flag_);
// 标记事件已经被记录
was_marked_for_recording_ = true;
// 更新设备索引为当前流的设备索引
device_index_ = stream.device_index();
}
// 阻塞等待指定流直到该事件之前的所有操作完成
void block(const Stream& stream) const {
if (!was_marked_for_recording_)
return;
// 检查传入流的设备类型与事件所属设备类型是否一致
TORCH_CHECK(
stream.device_type() == device_type_,
"Event device type ",
DeviceTypeName(device_type_),
" does not match blocking stream's device type ",
DeviceTypeName(stream.device_type()),
".");
// 调用后端接口执行阻塞等待操作
backend_.block(event_, stream);
}
// 查询事件状态:如果事件未被记录,则返回 true,否则调用后端接口查询
bool query() const {
if (!was_marked_for_recording_)
return true;
return backend_.queryEvent(event_);
}
// 返回底层事件指针
void* eventId() const {
return event_;
}
// 计算两个事件之间的经过时间(通常以毫秒为单位)
double elapsedTime(const InlineEvent& other) const {
TORCH_CHECK(
other.was_marked_for_recording(),
"other was not marked for recording.");
TORCH_CHECK(
was_marked_for_recording(), "self was not marked for recording.");
TORCH_CHECK(
other.device_type() == device_type_,
"Event device type ",
DeviceTypeName(device_type_),
" does not match other's device type ",
DeviceTypeName(other.device_type()),
".");
// 调用后端接口计算事件间耗时
return backend_.elapsedTime(event_, other.event_, device_index_);
}
// 阻塞等待当前事件完成
void synchronize() const {
if (!was_marked_for_recording_)
return;
backend_.synchronizeEvent(event_);
}
private:
// 底层事件指针,通常指向后端资源(例如 CUDA 事件)
void* event_ = nullptr;
// 后端实现对象,通过模板参数 T 提供
T backend_;
// 事件所属设备的类型(例如 CPU、CUDA 等)
DeviceType device_type_;
// 事件所属设备的索引,初始为 -1 表示未设置
DeviceIndex device_index_ = -1;
// 事件的标志,默认为 PYTORCH_DEFAULT
EventFlag flag_ = EventFlag::PYTORCH_DEFAULT;
// 标识是否已经记录过事件
bool was_marked_for_recording_ = false;
};
四 设备管理工具类-InlineDeviceGuard
c10/core/impl/InlineDeviceGuard.h 文件定义了 PyTorch 中的设备管理工具类 InlineDeviceGuard 和 InlineOptionalDeviceGuard,用于通过 RAII 机制安全地设置和恢复计算设备(如 CPU/GPU)。以下是核心要点:
InlineDeviceGuard:- 作用:在构造时将当前设备切换为指定设备,在析构时恢复到原始设备。该类通过模板参数 T(通常是具体的设备守护实现,如 CUDAGuardImpl 或 VirtualGuardImpl)来实现后端操作,从而支持静态或动态调度。
- 关键功能:set_device(), reset_device(), current_device(), original_device()。
InlineOptionalDeviceGuard:- 作用:与 InlineDeviceGuard 类似,不过它封装了一个可选的设备守护对象(使用 std::optional 包装),以支持可能未初始化的情况。
- 成员函数:和 InlineDeviceGuard 类似。