Pytorch 架构概览
Categories: Framework_analysis
一 pytorch 框架概述
1.1 pytorch 概述
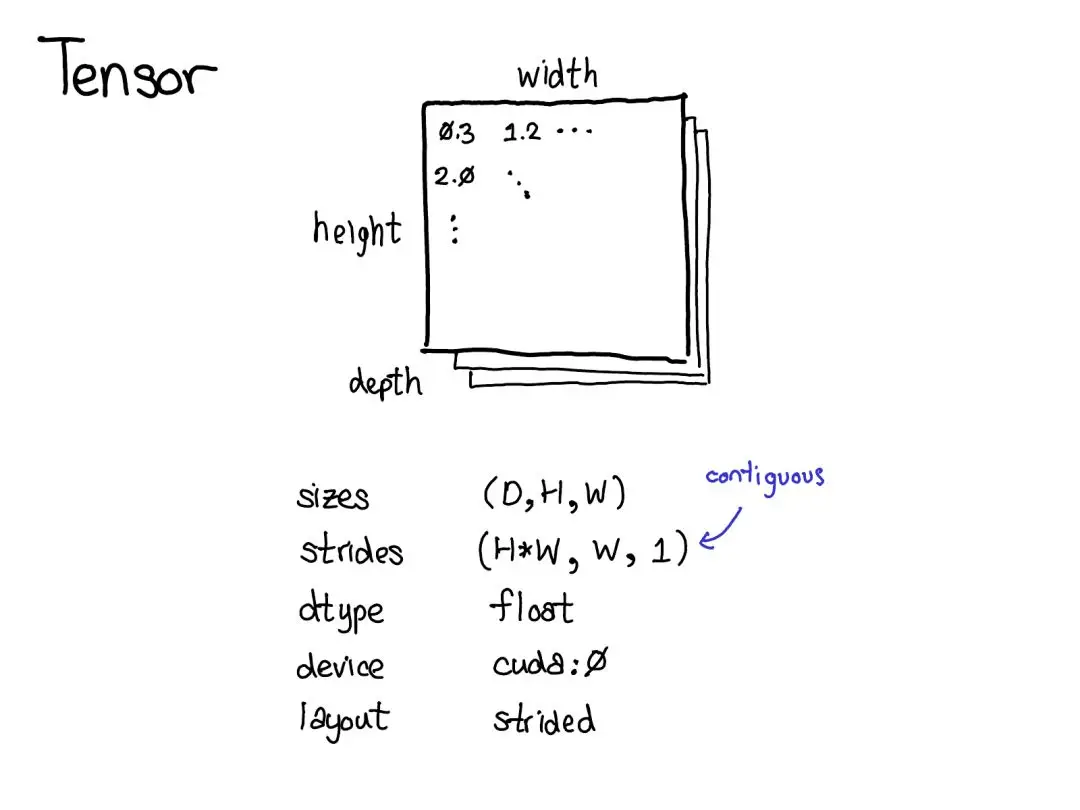
PyTorch 框架本质上是一个支持自动微分的张量库,张量是 PyTorch 中的核心数据结构, 它可以从两个角度理解:
- 直观上理解,其是一种包含某种标量类型(比如浮点数和整型数等)的 n 维数据结构。
- 代码实现上理解,张量可以看作是包含一些数据成员的结构体/类对象,比如,张量的尺寸、张量的元素类型(dtype)、张量所在的设备类型(CPU 内存?CUDA 内存?)和步长
stride等数据成员。
神经网络模型训练的两个主要特征:
- 张量计算 kernel 实现
- 自动微分系统实现
Pytorch 称为唯一主流的训练框架最主要的原因是它支持动态图,以及简单易用易开发。动态图的优点是支持实时打印张量计算结果。在 PyTorch中,我们之所以可以在计算的任意步骤直接输出结果。原因是,PyTorch 每一条语句是同步执行的,即每一条语句都是一个(或多个)算子,被调用时实时执行。这种实时执行算子的方式我们称为动态图或算子模式。
下图左侧部分总结了 pytorch 代码的执行流程,主要分为前端 python 部分和后端 c++ 部分。
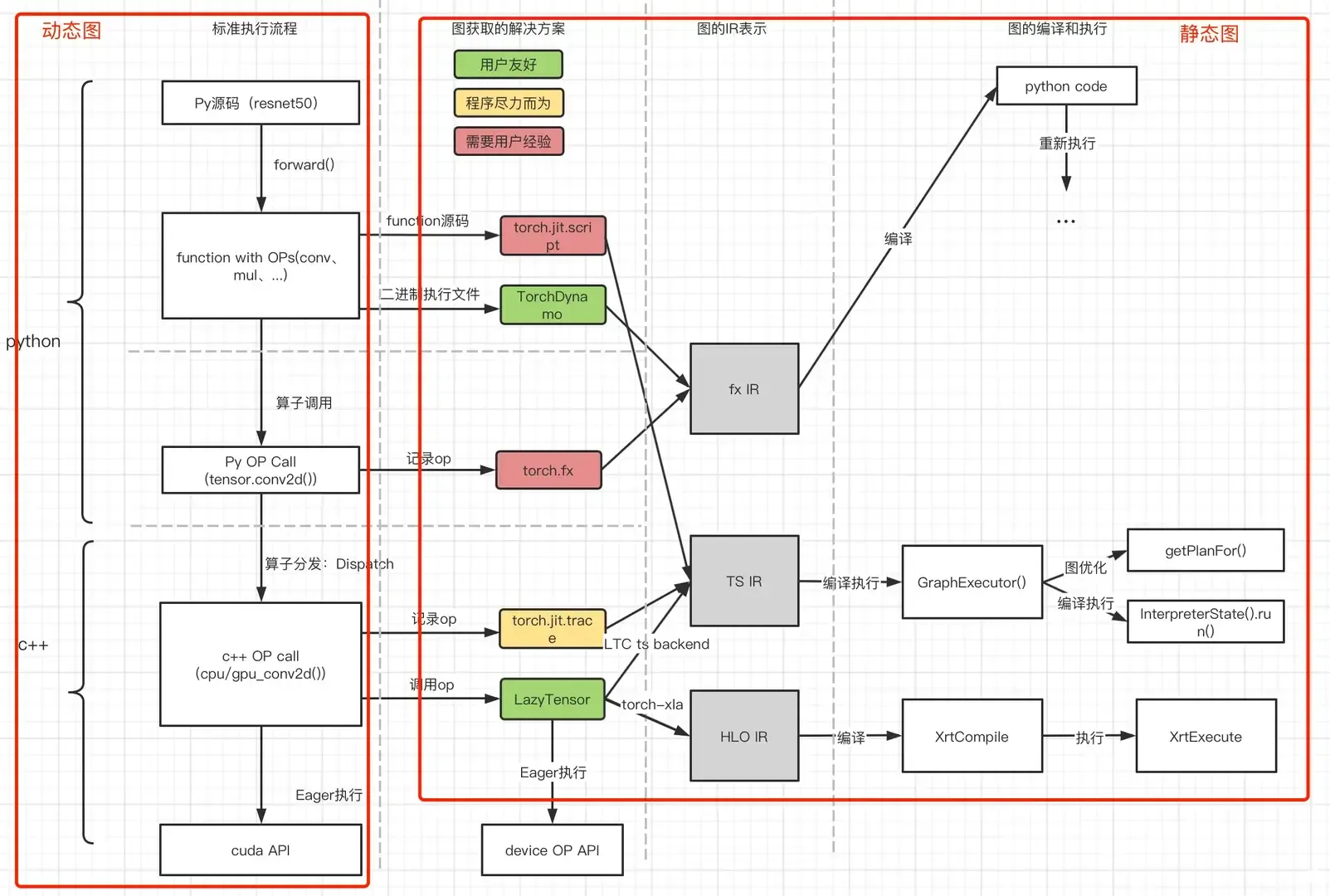
1.2 pytorch 前后端
在 pytorch 中前端指的是 pytorch 的 python 接口,用于构建数据集处理 pipeline、定义模型结构和训练评估模型的工具接口。
后端指的是 PyTorch 的底层 C++ 引擎,它负责执行前端指定的计算。后端引擎使用张量表示计算图的节点和边,并使用高效的线性代数运算和卷积运算来执行计算。后端引擎支持多设备(如 cpu、cuda、rocm等)执行计算,将 python 计算代码转换为底层设备平台能够执行的代码。
1.3 在 macOS 上的编译安装
1,前置安装条件:
Cmake 使用 brew 方式安装,不推荐用 conda 安装,版本优先推荐 3.31:
(torch) honggao@U-9TK992W3-1917 pytorch % cmake --version
cmake version 3.31.6
2,在环境中有 conda 的基础上,按照以下步骤编译按照 cpu 版本的 pytorch。
# 1, 创建名为 torch_dev 的虚拟环境,指定 python 版本为 3.12
conda create --name torch_dev python=3.12
conda activate torch_dev # 可不执行
# 2,安装依赖包
conda install cmake ninja
pip install -r requirements.txt
# 如果需要 torch.distributed 模块的功能
conda install pkg-config libuv
# 如果本地电脑 macos 系统中没有 cmake 或者版本低于3.15
brew install cmake
# 3,编译安装 torch 包(这个过程耗时非常严重)
MAX_JOBS=8 python setup.py develop # 使用 8 个并行任务同时编译
MAX_JOBS=8 python setpy.py install 编译源码,打好包,并安装(拷贝)到平台 python 环境中
和 install 方式不同之处在于,其不拷贝文件到平台环境,而是在 python 启动时直接将源码目录加到 python PATH 变量中。在 python 解释中通过 import sys 并打印 sys.path 可以看到pytorch 多了源码目录。

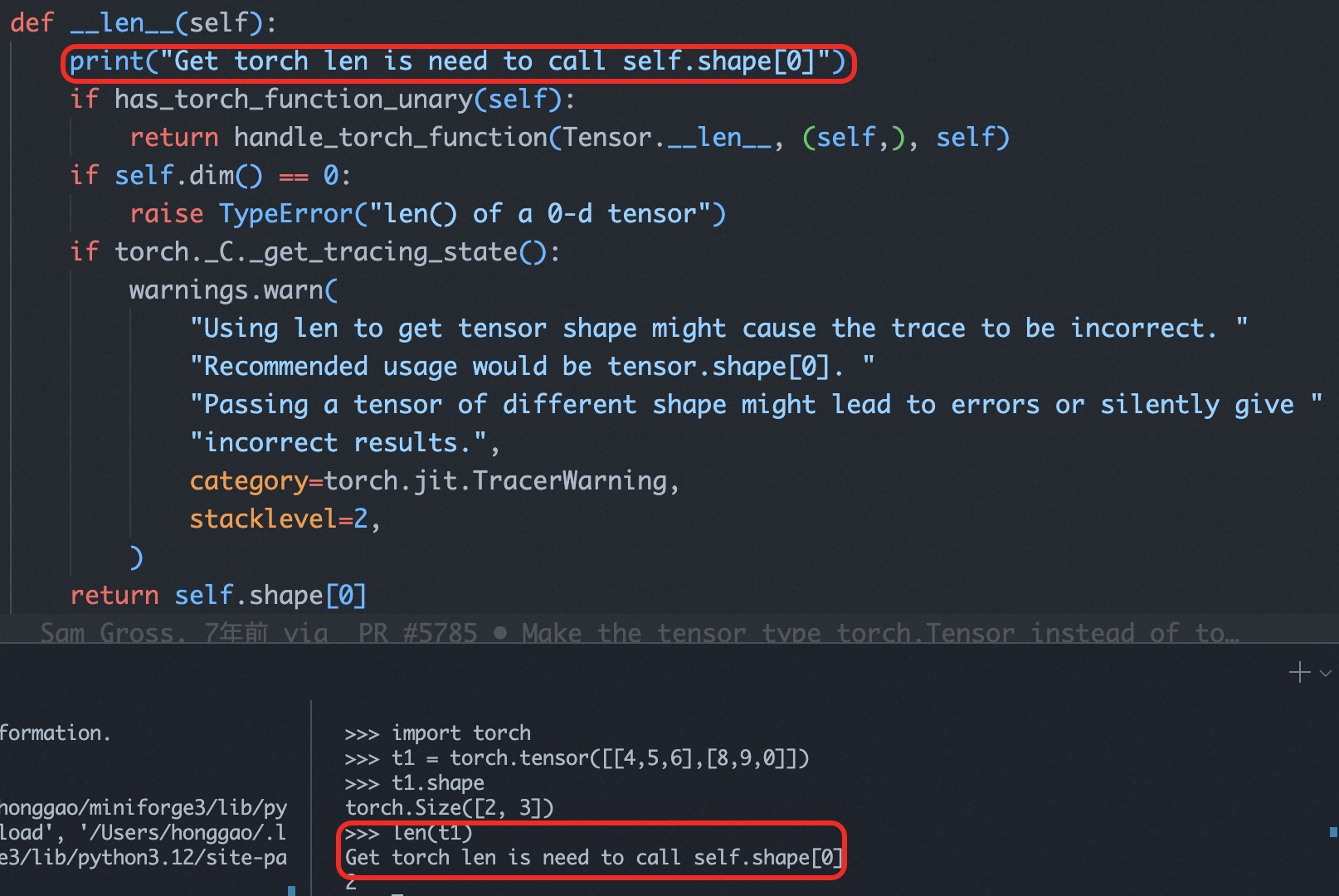
develop 编译安装方式可以让开发者在开发顶层 python 层逻辑代码时(比如要加入一个新的 nn module layer),在源码处做更改后即可立刻看到效果。
举个例子,我在 pytorch python 端的 Tensor 类代码的 __len__ 魔法方法中加入一段 print(“Get torch len is need to call self.shape[0]”) 代码后,在 python 中调用 len(tensor) 会立即生效,如下图所示:
二 pytorch 源码目录
PyTorch 2.x 的源码主要划分为多个顶级目录,每个目录承担不同的功能,通过 tree -L 1 -d 显示当前目录的 1 层子目录。
├── android # 在 Android 平台上编译和部署 PyTorch 有关
├── aten # ATen (“A Tensor”) 是 PyTorch 的张量库与算子库核心,实现了底层的张量数据结构、算子等基础。
├── benchmarks # 存放性能基准测试(benchmark)脚本及相关工具
├── binaries # 存放编译后生成的可执行文件或脚本、工具,可能也用作打包产物输出目录
├── build # 编译输出和中间产物
├── c10 # PyTorch 的核心基础库,包含常用数据结构(TensorImpl, Storage)和调度器(Dispatcher)、设备适配等的通用实现。
├── caffe2 # Caffe2 的遗留子目录,包含 Caffe2 自己的 core, utils, serialize 等部分
├── cmake # 存放 CMake 脚本和配置模块
├── docs # 存放文档
├── functorch # Functorch 项目集成到 PyTorch 源码,提供可对函数进行变换(vmap, grad等)的函数式功能和原型。
├── mypy_plugins # 存放mypy(Python 静态类型检查)的插件或自定义类型规则
├── scripts # 辅助脚本
├── test # PyTorch 的 测试用例目录:单元测试、集成测试
├── third_party #第三方依赖库 源码
├── tools # 构建工具与脚本库,包含 build 系列脚本、jit 工具、onnx 工具、code_coverage, linter 等
├── torch # PyTorch Python 包源码的核心实现
├── torch.egg-info
└── torchgen # PyTorch 算子代码生成相关脚本和生成文件目录,如算子注册、shape 函数生成、static_runtime、decompositions 等。
2.1 pytorch 核心目录概述
虽然第一级的子目录很多,但是对于开发者来说,最核心和重要的子目录就那几个,简单总结下其作用和相互关系:
c10/:c10 指的是 caffe tensor library,相当于 caffe 的 aten, PyTorch 的核心基础库目录。- c10 子目录提供了在各平台通用的基础构件,包括Tensor 元数据和存储实现、调度分发机制(dispatcher)、流(Stream)、事件(Event)等。
- 它其实是 PyTorch 和 Caffe2 合并后抽象出的统一核心层,“c10” 名字取自 “Caffe2” 与 “A Ten”的谐音(
C Ten)。 - c10 本身不包含算子的实现,它更多的是提供一些辅助张量自动微分机制的抽象模块和类。
aten/:ATen (“A Tensor”) 库目录。ATen 是 PyTorch 的张量运算核心库(C++ 实现),提供张量及其操作的定义和实现。它不直接包含自动求导逻辑,主要关注张量的创建、索引、数学运算、张量运算等 kernel 操作和实现的功能。aten/src/ATen 下有核心子目录:ATen/core:ATen 的核心功能(部分正逐步迁移到顶层的 c10 目录)。ATen/native:分算子(operators)的native实现。如果要新增算子,一般将实现放在这里。根据设备类型又细分子目录:native/cpu: 并非真正意义上的 CPU 算子实现,而是经过特定处理器指令(如 AVX)编译的实现。。native/cuda: 算子的 CUDA 实现。native/sparse: COO 格式稀疏张量操作在 CPU 和 CUDA 上的实现。native/quantized: 量化张量(即 QTensor)算子的实现。
torch/:真正的 PyTorch 库,除 csrc 中的内容外,其余部分都是 Python 模块,遵循 PyTorch Python 前端模块结构。csrc: 构成 PyTorch 库的 C++ 文件。该目录树中的文件混合了 Python 绑定代码和大量 C++ 底层实现。有关 Python 绑定文件的正式列表,请参阅setup.py;通常它们以 python_ 为前缀。jit: TorchScript JIT 前端的编译器及前端。一个编译堆栈(TorchScript)用于从 PyTorch 代码创建可序列化和可优化的模型。autograd: 反向自动微分的实现。详见 README。api: PyTorch 的 C++ 前端。distributed: PyTorch 的分布式训练支持。
tools: 供 PyTorch 库使用的代码生成脚本。
2.2 c10 核心基础库
c10 作为 PyTorch 框架的核心基础库,其包含多个子模块:
c10/core/:核心组件,定义了 PyTorch 核心数据结构和机制。例如包含TensorImpl(张量底层实现类)、Storage(张量存储)、DispatchKey和Dispatcher(动态算子调度)、设备类型Device、类型元信息TypeMeta等基础定义。c10/util/:工具模块,提供通用的 C++ 实用组件。如 intrusive_ptr 智能指针、UniqueVoidPtr通用指针封装、Exception异常处理、日志和元编程工具等,供整个框架使用。c10/macros/:宏定义模块,包含编译配置相关的宏。例如根据操作系统和编译选项生成的 cmake_macros.h,以及 C10_API, TORCH_API, CAFFE2_API 等符号导出控制宏。c10/cuda/, c10/hip/, c10/metal/, c10/xpu/ 等:特定设备平台支持代码, 这些目录有助于在 c10 层面适配不同硬件平台。例如:- c10/cuda 中包含 CUDA 后端初始化、流管理等与 CUDA 设备相关的基础功能;
- c10/hip 类似地对应 AMD 的 HIP;
- c10/metal 针对苹 Metal 后端;
- c10/xpu 则可能用于其他加速器(如 Intel XPUs)。
c10/mobile/:移动端支持代码,为在移动/嵌入式场景下裁剪和优化 PyTorch 而设。c10/test/:c10 本身的一些单元测试代码。
2.3 _C 模块概述
在 PyTorch 中,_C 模块(通常以 torch._C 命名)是 PyTorch 的核心 C/C++ 层的接口。它是一个经过编译的动态库(例如在 Linux 下为 .so 文件,在 macOS 下为 .dylib,在 Windows 下为 .dll),用于向 Python 层暴露底层高性能实现的功能。
实现原理:
- C++/CUDA 内核实现:PyTorch 的大部分核心运算、数据结构和算法均在 C++ 层实现,并且支持 CPU/GPU/XPU 多设备后端。
- 绑定机制:使用
pybind11将C++类和函数暴露为Python模块中的对象和方法。 - 编译与打包:在构建过程中,通过
setuptools或CMake调用编译器将 C++ 源文件编译成动态库,并在打包时将其放入 Python 包(例如torch/_C.so),从而实现跨平台分发。
三 从 torch.tensor 理解前后端交互
“import torch” 时重要的初始化
当在 python 代码中执行 import torch 时,import 会去寻找 */site-packages/torch/__init__.py 文件,其是 PyTorch 的顶层入口文件。而 __init__.py 文件的作用是完成 PyTorch 的模块初始化与全局配置和子模块加载过程等。具体来说,负责完成以下主要任务:
- 模块初始化与全局配置:读取和设置版本信息、配置信息,以及初始化日志、环境变量等全局状态。
- 动态库加载: 加载
_C模块时,会调用其中的初始化函数(例如PyInit__C()),完成低层核心组件的初始化。 - API 封装和命名空间构建。
- 子模块导入:将 torch.nn、torch.optim、torch.cuda 等子模块导入到顶层命名空间。
- 错误处理和兼容性支持:确保在不同操作系统、不同 CUDA/ROCm 环境下的兼容性,并给出相应的警告或提示信息。
__init__.py 文件中包含了多种与张量初始化相关的关键组件,以下是对主要部分的总结和详细解释:
- 核心 Tensor 类的导入与定义
from torch._tensor import Tensor # 导入核心 Tensor 类
这一行导入了 PyTorch 的核心 Tensor 类,它继承自 C++ 实现的 torch._C.TensorBase,是所有张量操作的基础。张量创建时都会实例化这个类。
- 动态链接库加载
def _load_global_deps() -> None:
#############省略代码############
if USE_GLOBAL_DEPS:
_load_global_deps()
from torch._C import * # noqa: F403
- 符号张量支持
class SymInt: ...
class SymFloat: ...
class SymBool: ...
def sym_int(a): ...
def sym_float(a): ...
def _constrain_as_size(symbol, min=None, max=None): ...
- 设置设备和数据类型配置函数定义
def set_default_device(device):
# 设置默认设备,影响张量创建时的默认位置
_GLOBAL_DEVICE_CONTEXT.device_context = device_context
def set_default_dtype(d: "torch.dtype") -> None:
# 设置默认浮点数据类型
这些函数会控制新创建张量的默认设备和数据类型。例如,
- set_default_device(‘cuda’) 会使新张量默认创建在 GPU 上。
- set_default_dtype(torch.float64) 会改变浮点张量的默认精度。
- set_default_tensor_type 是一个较旧的 API,现在推荐使用 set_default_dtype 加 set_default_device 的组合来代替。
- 张量存储类定义
现在推荐使用 TypedStorage 和 UntypedStorage 作为 PyTorch storage object。
from torch.storage import (
_LegacyStorage,
_StorageBase,
_warn_typed_storage_removal,
TypedStorage,
UntypedStorage,
)
torch._C 分析
在我的 macos 电脑中对应的就是 torch/_C.cpython-312-darwin.so 文件,文件名指明了编译它的 python 版本和所在平台系统,这种命名是 python c module 的一种规范。
torch.Tensor 类的初始化和实现
Python中的类型也是对象,类型是PyTypeObject对象。
torch/_tensor.py 是 PyTorch 中定义和包装张量(Tensor)的 Python 端接口文件,它连接了 C++ 内核实现与 Python 用户接口。总体来说,
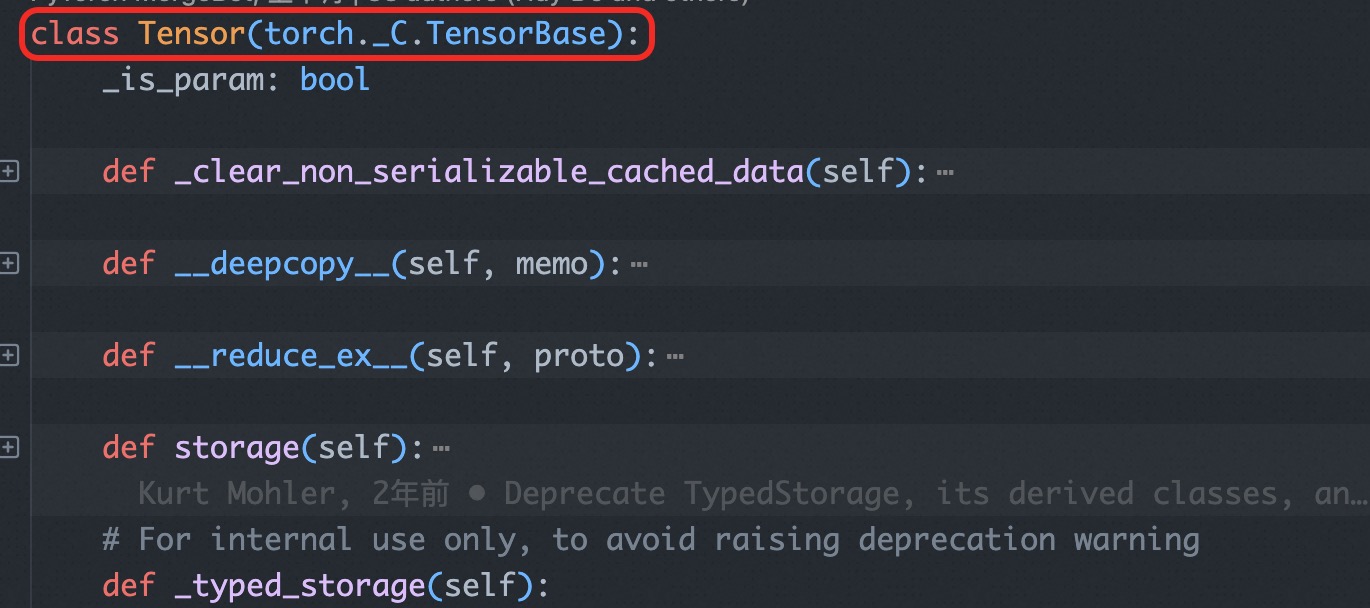
_TensorBase 类的实现是在 torch/_C/init.pyi 中。
torch/_C/init.pyi 作文件是 PyTorch 对外提供的 C++ 扩展模块接口的类型提示文件(stub file),用于描述 torch._C 模块中 C++ 实现的各个函数、类和常量的类型定义信息,但是没有具体实现。
PyTorch 通过 pybind11 将 C++ 函数、类暴露给 Python,在这个过程中部分信息可以被用来生成 .pyi 文件。
下图可以看出 TensorBase 类真正的实现是在 torch/csrc/autograd/python_variable.cpp 中。
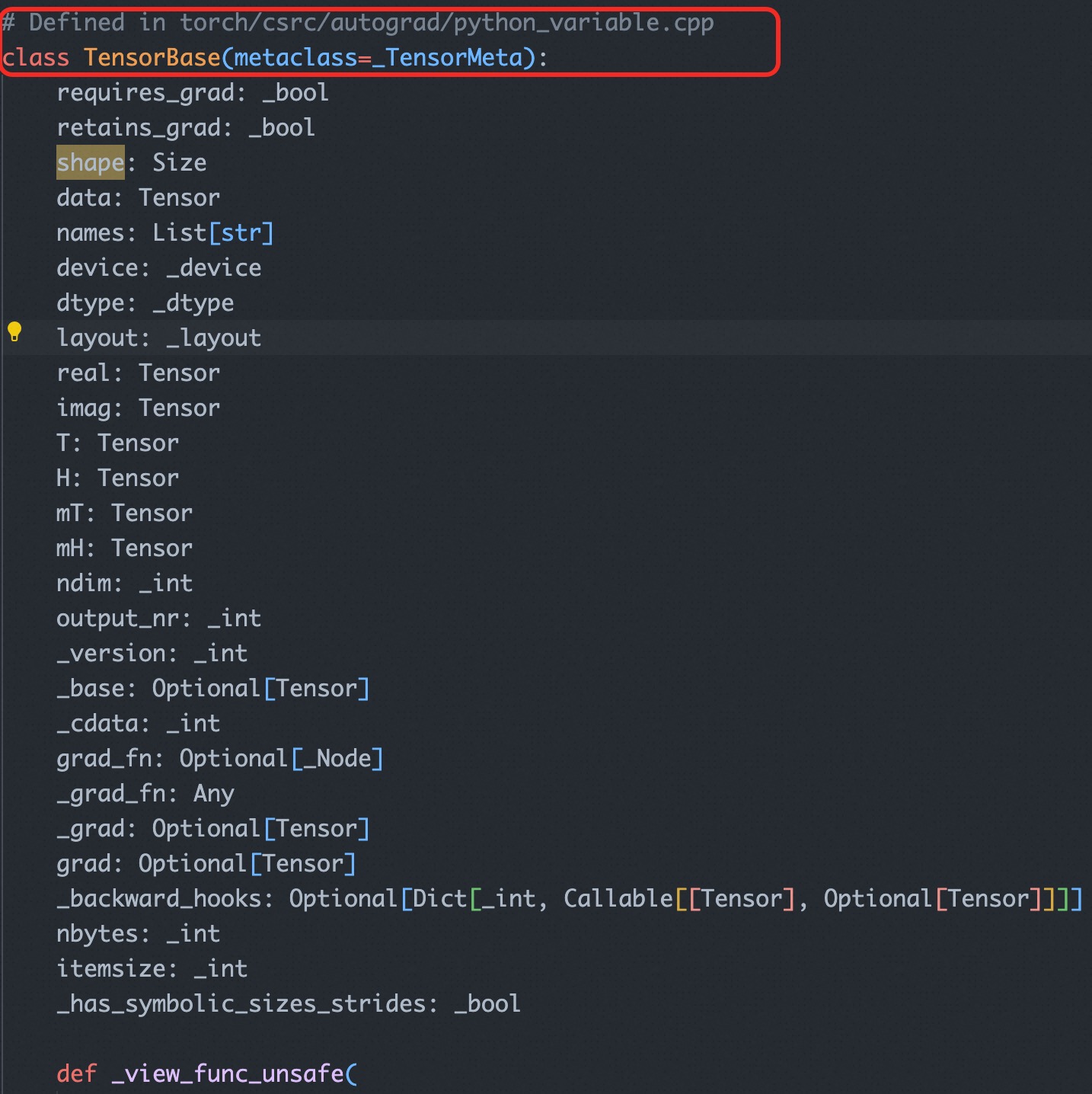
在 python_variable.cpp 文件中,可以看到 PyTorch 实际是用了 pybind,将 C++ 和 Python 进行交互的。
“THPVariable”全称为“Torch Python Variable”,用于表示PyTorch源码中用于Python绑定的 C 结构体类型,其代表了 Python 层中的Tensor对象(历史上称为Variable)
pytorch python 中的 tensor 实现是继承自 _C module 的 _TensorBase class,而 _TensorBase 是在 C++ 代码中实现并添加到 _C 模块中,如下:
bool THPVariable_initModule(PyObject* module) {
THPVariableMetaType.tp_base = &PyType_Type;
if (PyType_Ready(&THPVariableMetaType) < 0)
return false;
Py_INCREF(&THPVariableMetaType);
PyModule_AddObject(module, "_TensorMeta", (PyObject*)&THPVariableMetaType);
static std::vector<PyMethodDef> methods;
THPUtils_addPyMethodDefs(methods, torch::autograd::variable_methods);
THPUtils_addPyMethodDefs(methods, extra_methods);
THPVariableType.tp_methods = methods.data();
if (PyType_Ready(&THPVariableType) < 0)
return false;
Py_INCREF(&THPVariableType);
PyModule_AddObject(module, "TensorBase", (PyObject*)&THPVariableType);
Py_INCREF(&THPVariableType);
PyModule_AddObject(module, "_TensorBase", (PyObject*)&THPVariableType);
torch::autograd::initTorchFunctions(module);
torch::autograd::initTensorImplConversion(module);
torch::utils::validate_numpy_for_dlpack_deleter_bug();
return true;
}
THPVariable_initModule 里相关操作, 初始化 THPVariableType 类类型,增加 THPVariableType 计数等是 C API 往 python 模块里添加类类型的标准做法。
下述代码是实现了往 python 的 module 中添加了名为 “TensorBase” 的类类型对象 THPVariableType,第一个参数 module 是 _C module 类型。
PyModule_AddObject(module, "_TensorBase", (PyObject *)&THPVariableType);
因为 Tensor 类继承自 _TensorBase,所以在 Tensor 被实例化之前,必须先完成 _TensorBase 的初始化。又因为 _TensorBase 是属于 _C 模块的一部分,所以在代码 torch/__init__ 中,当执行 from torch._C import * 时,实际上也完成了 _TensorBase 的初始化。
当在 Python 中执行 import torch._C(或间接通过 import torch 导入时)时,Python 解释器会自动调用 PyInit__C() 来初始化该模块。
PyInit__C() 的具体实现是在 torch/csrc/stub.c (关键源文件)中,其包含以下内容:
- 构建过程:在编译过程中,
stub.cpp会被编译成目标文件(.o 文件),与其他目标文件一起链接生成最终的动态库,例如文件名为_C.python-37m-x86_64-linux-gnu.so的共享库。 - 多个目标文件:通常构建这样的大型项目时,除了
stub.c之外,还会有其他源文件编译生成目标文件。这些目标文件一起被链接成最终的动态库_C.python-37m-x86_64-linux-gnu.so,其中stub.c中包含的PyInit__C()函数就是模块初始化的入口。
torch/csrc/stub.c 文件内容如下:
#include <Python.h>
extern PyObject* initModule(void);
#ifndef _WIN32
#ifdef __cplusplus
extern "C"
#endif
__attribute__((visibility("default"))) PyObject* PyInit__C(void);
#endif
PyMODINIT_FUNC PyInit__C(void)
{
return initModule();
}
Python 3.x 扩展模块初始化规范
根据 Python 3.x 的 C API 规范,每个用 C 或 C++ 编写的扩展模块都必须提供一个初始化函数,该函数的名称必须以 PyInit_ 开头,后面紧跟模块的名称。例如:
- 如果模块名称为
_C,那么初始化函数的名称就必须是PyInit__C()。 - 这个函数在模块导入时由 Python 解释器自动调用,用来创建并返回一个模块对象。
假设我们有一个 C 扩展模块初始化函数 PyInit__C,其部分代码如下:
static struct PyModuleDef moduledef = {
PyModuleDef_HEAD_INIT,
"_C", /* m_name */
"Module for PyTorch core.", /* m_doc */
-1, /* m_size */
NULL, /* m_methods */
NULL, /* m_reload */
NULL, /* m_traverse */
NULL, /* m_clear */
NULL, /* m_free */
};
PyMODINIT_FUNC PyInit__C(void) {
PyObject *module = PyModule_Create(&moduledef);
if (!module)
return NULL;
// 将 THPVariableType 绑定为 _TensorBase 属性
if (PyModule_AddObject(module, "_TensorBase", (PyObject *)&THPVariableType) < 0) {
Py_DECREF(module);
return NULL;
}
// ... 其他初始化代码 ...
return module;
}
初始化函数会负责执行模块内的各项初始化操作,比如设置模块的全局变量、注册函数、创建类型对象等。只有初始化函数返回一个有效的模块对象后,Python 才能将该模块添加到全局命名空间中供后续使用。
_C 模块表示是用 C++ 编写的 Python 模块,根据 Python 3.x 的 API 规范,模块的初始化入口必须以 “PyInit” 作为前缀,紧跟模块名称。在这个例子中,对应的初始化函数即为 PyInit__C()。该函数正是定义在 stub.cpp 文件中,而这